As I’ve been training on the initial results of the speech gathering app, one of the challenges has been aligning the recordings. There can be a delay between somebody hitting record and saying a word, or they can say it very quickly and leave a large gap at the end of the audio file. To improve the results of the training, I wanted to find a way to standardize the start of a word in my input files, since that would also let me shorten the window of audio I’m looking at, and so reduce the overall compute time.
I looked into advanced speech alignment tools like Sphinx, but they had some pretty gnarly dependencies which I was hoping to avoid in a beginning tutorial. They also had a lot of assumptions built in that didn’t transfer well to single word commands, most didn’t have many prebuilt models, and in general they weren’t easy to integrate.
Looking at visualizations of the waveforms from the recordings using the great Fission app, it usually appeared pretty obvious which section had the word, and which parts were background.
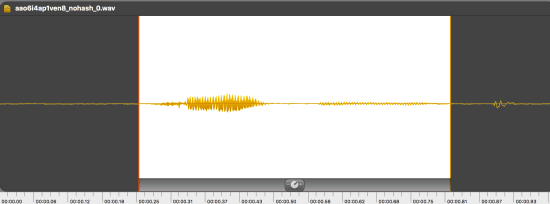
In this example, the word is in the highlighted portion, and the only other peaks are a noisy click near the end. I was hoping to find an existing tool that would recognize this kind of pattern and help me remove the background, leaving only the part I wanted. I looked at both sox and ffmpeg’s silenceremove filters, but I couldn’t find one that worked well:
– Sox clipped initial sections of the spoken word, since there was a delay before it recognized ‘non-silence’.
– There was an option to avoid this with ffmpeg, but reliably detecting silence meant normalizing all my clips to a standard volume level, which wasn’t something I wanted to do to speech samples.
I also couldn’t specify that I wanted a particular length of clip. In my case, I knew I wanted a second-long result, because that’s what my models take in, and all the words should fit in that length. Most of the tools out there seemed designed to remove gaps in recorded music, but intuitively it felt like my problem was more like ‘give me the second-long section with the most relevant audio in it’.
As I thought about this, I realized that the speech should be the loudest sustained part of the recording, so if I could slide a contiguous window through the audio data and pick the section that was loudest in total, I might get good results.
To visualize what I mean, imagine a simplified waveform of a two-second long clip:
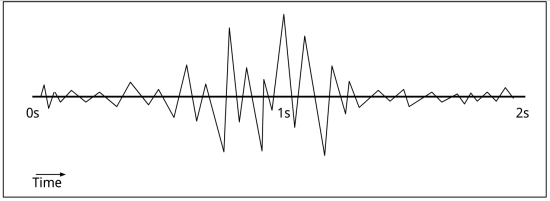
To my untrained eye, it’s clear that the middle section has the most going on. To turn that into a useful definition, I estimated the volume at each point in the file using the absolute of the PCM value (volume = abs(value)) and then walked through the clip looking at the total of those volumes for a one-second range. By picking the point where the sum total of the volumes is highest:
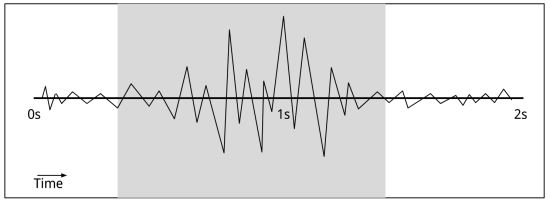
You can clip down to a short section with the loudest audio in it:
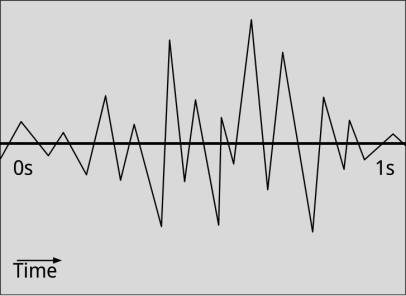
I’m sure this particular wheel has been invented many times before, but I couldn’t find it in my searches, so I wanted to leave a trail of breadcrumbs for anyone else stuck with a similar problem. Hopefully people with more experience in this domain will also leave comments offering other suggestions!
The code itself is very straightforward, and I’ve put it up at https://github.com/petewarden/extract_loudest_section. The command line interface has only been designed for my particular use case, with one second hardcoded as the desired window length, only folders of .wavs supported, and no build file for anything other than OS X. It should be easy to port to your own system though, it doesn’t have any dependencies outside of Posix and the C/C++ standard libraries.
The only real point of interest is that it doesn’t recalculate the whole sum at every sample, instead it keeps a running total by subtracting the value leaving the interval as it moves forward in time, and adding in the new volume, which keeps the latency very low.
float current_volume_sum = 0.0f;
for (int64_t i = 0; i < desired_samples; ++i) {
const float input_value = input[i];
current_volume_sum += fabsf(input_value);
}
int64_t loudest_end_index = desired_samples;
float loudest_volume = current_volume_sum;
for (int64_t i = desired_samples; i < input_size; ++i) {
const float trailing_value = input[i - desired_samples];
current_volume_sum -= fabsf(trailing_value);
const float leading_value = input[i];
current_volume_sum += fabsf(leading_value);
if (current_volume_sum > loudest_volume) {
loudest_volume = current_volume_sum;
loudest_end_index = i;
}
}

The code looks a bit buggy. You’re taking the absval of the square in the initial loop, then absval (as you say in the text). I wondered why you don’t take squares all the time instead of abs. Sure, you have to do an extra multiply to drop the term but I kind of doubt that a fmul is really much more than fabs these days and L2 norm seems cleaner. I do happen to have experience with audio, but I haven’t heard or thought about this particular problem before. Other than the comments I already made, your approach seems fine.
Thanks Curtis! I had updated the code to fix that squared term in the first fabsf(), but hadn’t changed the example snippet, so I’ve just changed that now.
I’ll admit I was a bit unsure whether the L2 norm would be better in this case too, I appreciate your perspective, especially as I’m coming to this as an audio neophyte.
I am curious how to train the single word audio when audio recording is ready?
I landed on you blog following a suggestion from Aurélien Géron’s book on machine learning I’m currently reading.
This post grabbed my attention immediately. I confirm, like you mention, that this wheel has been invented many times ago, as I’m the author of one such tool: https://github.com/amsehili/auditok