As soon as I received my first Raspberry Pi, I knew that it would be a wonderful platform to bring AI into the physical world. Since the initial hardware didn’t have good CPU support for fast arithmetic, I ended up writing code that ran on the GPU so I could get the speed I needed for early deep learning vision models. That was in 2014, and since then the capabilities of both Pis and AI have skyrocketed, and I’m even more convinced that there’s massive potential in combining them. To show you why, I’d like to demonstrate how open-source AI running locally on a Pi has solved some practical problems I’ve run into, and hopefully inspire you to build your own projects using the new possibilities.
Pis are great for systems that need to be out in the world, doing specialized jobs. I’ve seen them work well in all sorts of roles, from badge scanners to wildlife cameras. I even run a class that teaches students all about edge AI using the platform. While the boards are generally easy to use, the most frustrating part for the students and instructors is the setup process. While the latest imager makes it straightforward to configure settings like a wifi network to join or enabling SSH when you’re flashing a card, getting the students to the point where they can connect to their Pi using VS Code from their laptop could often take multiple sessions. The biggest problems were:
- There were different networks in the lab and in the students’ dorm rooms, so it wasn’t enough to hardcode a single SSID and password on the SD card.
- You need the local IP address of the Pi to SSH into it from a laptop, but it can change dynamically every session. Using “<Pi name>.local” would sometimes work, but some networks didn’t support this kind of lookup, and even if they did it required coordination between the students to avoid name clashes.
- It was easy to forget to set the configuration so that wifi and SSH were available, and since the instructors didn’t always know what network and password they’d be using in the class ahead of time, we couldn’t pre-flash a bunch of cards to speed up students on-boarding.
A lot of these issues were solvable if you plugged the devices into a monitor, mouse, and keyboard, but this has its own problems. It meant we needed to provide that equipment to all students during class, and allow them to take it all home too, so they could update the configuration for their personal networks. It also required an extra power socket per student, for the monitors, which added up in a class where we already had to bring in a cart full or power strips. The monitor connections also weren’t always plug and play, we found we often needed to boot with a screen attached to have the display recognized.
This isn’t just an educational problem either. One of the reasons that I believe the Internet of Things failed is the setup tax involved in getting smart devices running. According to manufacturers I’ve worked with, less than 30% of their smart appliances ever get connected to the internet, because the process of downloading an app, setting up an account, connecting over Bluetooth, and then typing in the wifi name and password takes too long, and is too errorprone. Even professional installers sometimes struggle with configuration in enterprise and industrial environments.
So, what can AI do to help? One of the biggest developments in AI over the last few years has been the development of highly-accurate open-source Automatic Speech Recognition (ASR) models, also known as Speech to Text (STT). OpenAI were the pioneers in this area, releasing the family of Whisper models in 2022. These offered accuracy that was competitive with the models used internally by large tech companies like Google and Apple. These new models allowed startups to begin building voice applications that had never been possible before, and led to a new generation of dictation and meeting note tools like WhisprFlow.
One of my dreams as I dealt with all of the configuration issues was a voice-based system that would allow me to simply plug in a headset and set up everything by talking to a Pi. Whisper made this dream seem more realistic, but as I tried to use the models on local hardware, I realized that they were too slow for any kind of interactive application.
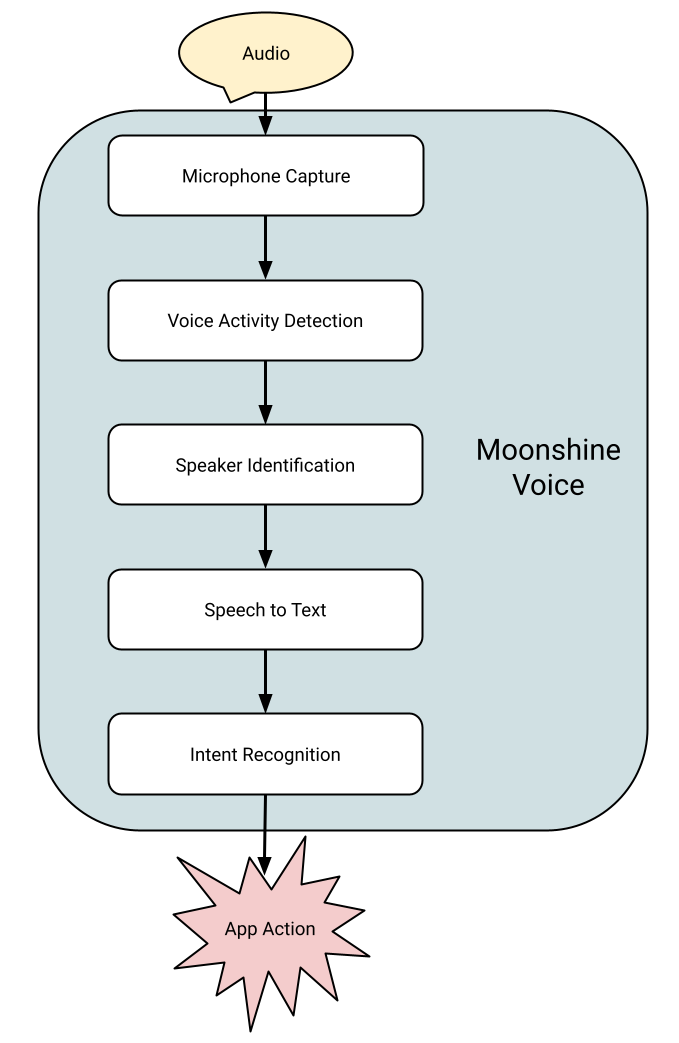
To address that my startup trained new models from the ground up, designed specifically for realtime applications on affordable hardware. These Moonshine models are smaller than Whisper (our high-end is 250 million parameters versus OpenAI’s 1.5 billion) while offering better accuracy. We also implemented a streaming approach, where a lot of the work is done while the user is still talking, so we can return results even faster. This allows us to return more accurate results than Whisper v3 Large, in just 800 milliseconds on a Pi 5, whereas even the less-accurate Whisper Small takes over ten seconds.
I was excited because this meant I could finally build a responsive voice agent that runs locally on a Pi, something offline-first, and fast and flexible in how it responds. This kind of system needs more than just an STT model, it needs to decide what the user means and respond by taking actions and talking back with a Text to Speech (TTS) system. The Moonshine Voice framework includes modules for conversation flow and TTS, so I was able to use it to build pi-help-bot, a local voice agent for network configuration on the Pi.
The application listens to the microphone for commands like “What is my IP address?” or “Help me set up the wifi please”, figures out what actions to take, and responds appropriately by talking to the user. It’s written as a Python script, and here are some snippets that show how it works:
def report_ip_address(d: Dialog):
ip = _find_local_ip()
if ip is None:
yield d.say("Sorry, I couldn't find a local IP address.")
return
speech_ip = re.sub(r"(\d)", r"\1 ", ip.replace(".", " dot "))
yield d.say([
f"Okay. Your local IP address is {speech_ip}. ",
f"To repeat, that's {speech_ip}."
])
dialog_flow.register_flow("What is my IP address?", report_ip_address)
This code is a function that uses the netifaces library to figure out the Pi’s address on the local network, so instead of having to connect a keyboard and display or decode the output of nmap, you can ask the question and hear the result, all in just a few seconds. Unlike older voice interfaces, the phrases the user says don’t have to be exactly the same as the one you register an intent with. Instead the framework matches incoming speech against a small, local LLM, so that variations “Hey, can you tell me what my IP is?” work too. This was important to me because one of my biggest frustrations using voice interfaces like Alexa is that they need particular wording to trigger commands, but these wordings aren’t discoverable, so figuring out how to make something happen can require a lot of patience.
The IP address command is the simplest kind of conversational flow, where the user asks a question and the system immediately responds. Not all interactions can be handled as simply as this one though. Here’s another example that shows how to implement something that needs multiple questions, answers, and confirmations, connecting to a new wifi network:
def connect_to_wifi(d: Dialog): input_ssid = yield d.ask("What's the name of your Wi-Fi network? Say list if you want to pick from a list or spell if you want to spell out the start of the name") input_ssid = input_ssid.strip() networks = _scan_wifi_networks() if input_ssid.lower().strip(string.punctuation) == "list": yield d.say("Say yes to the network you want to connect to.") for network in networks: if (yield d.confirm(f"{network}?")): input_ssid = network break elif input_ssid.lower().strip(string.punctuation) == "spell": input_ssid = yield d.ask("Spell out the start of the network name.", mode=SPELLED) found_ssid = fuzzy_match_network(input_ssid, networks) if found_ssid is None: yield d.say(f"Sorry, I couldn't find a matching network for {input_ssid}.") return password = yield d.ask( f"Please spell the Wi-Fi password for {found_ssid} one character at a time, and say done when finished.", mode=SPELLED, ) yield d.say(f"Connecting to {found_ssid}.") result = subprocess.run( ["sudo", "nmcli", "device", "wifi", "connect", found_ssid, "password", password], capture_output=True, text=True, timeout=30, ) if result.returncode == 0: yield d.say(f"Connected to {found_ssid}.") else: yield d.say( f"Sorry, I wasn't able to connect to {found_ssid}. " "Please check the network name and password and try again." )dialog_flow.register_flow("Connect to Wi-Fi", connect_to_wifi)
Hopefully you can follow the logic as it walks the user through providing the information required, but you might be wondering about those yield statements. Those hand back control to the dialog controller while the script is waiting for user responses, so the rest of the application isn’t blocked.
The end result is a local voice agent that will listen out for configuration questions and commands, allowing users to set up a Pi for remote access with just a headset. For ease of use, I’ve begun customizing the images I burn to SD cards so that this script automatically starts on boot. This means I can start setting up new devices immediately after powering them on.
I hope this gave you some ideas about how a local voice interface could help with problems you face. For further information check out the Moonshine Voice project on GitHub to see full documentation on the library, and please give us a star while you’re there, it helps us keep working on this project.