A friend recently introduced me to Andy Goldsworthy’s work, through the Rivers and Tides documentary, so I was excited to see some of his ‘land art’ up close in San Francisco’s Presidio Park. The official site has some great background, but I couldn’t find a good guide to exploring all three of his scattered pieces, so here’s a quick rundown and map showing how I ended up navigating around. The hike itself is roughly two miles long, with well-maintained trails, and a few hundred feet of climbing but nothing too terrible.
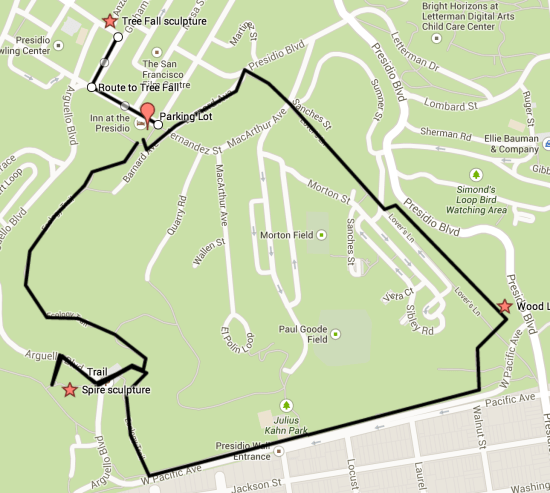
Parking can be tough in the Presidio, but thankfully it was a rainy Super Bowl Sunday, so I found a spot in a small two-hour free parking section behind the Inn at the Presidio. I was actually originally aiming for the Inspiration Point parking lot, but that turned out to be closed for construction, so I was thankful to find something close to where I needed to be. There is plenty of paid parking nearer the Disney museum too, just a couple of blocks away, if you do get stuck.
There’s a trailhead and map at the parking lot, and from there I headed up the Ecology Trail, a reasonably steep fire road towards Inspiration Point. Once I reached the under-construction lot there, the view was beautiful, even on a wet day, looking out over Alcatraz and the bay. If you look away from the water, you should be able to see the top of Andy’s ‘Spire’ sculpture. As of February 2014, the construction made the normal trail to it inaccessible, so I ended up hiking a couple of hundred yards right along Arguello Boulevard, and then taking a use trail up to the main trail. It’s easy to navigate with the peak of the sculpture to guide you at least.
The piece itself is a tall narrow cone of unfinished tree trunks, all anchored deep in the ground and leaning in on each other. My first visit was at twilight, which gave it a very stark and striking silhouette, and it pays to find a spot where you can see it against the horizon, it’s hard to take it all in up close.
I then headed back to the Inspiration Point parking lot, and went back down to rejoin the Ecology trail, and continued along it almost to the edge of the park. I then followed the trail that parallels West Pacific Avenue all the way to the Lovers Lane bridleway. Just on the other side of Lovers Lane is the second Goldsworthy work, ‘Wood Line’. It’s a series of tree trunks with their barks stripped, arranged in a continuous snaking line for a thousand feet or so, starting and ending by disappearing into the earth. The look alone is very striking, but I also couldn’t resist the urge to walk along the whole length. I’d normally be horrified at the thought of clambering on public sculpture, but it didn’t feel like a bad way to interact with the work, it’s so open to the elements, and it forced me to look closely at it just to avoid slipping off!

Photo by Joanne Ladolcetta
Afterwards, I continued down Lovers Lane to its end at Presidio Boulevard, and then headed left along Barnard Avenue. There are a set of steps on the right that lead back to the parking lot, so I stopped by the car and dropped off my pack. The final piece is inside the old Powder Magazine, a couple of blocks away at the corner of Anza and Sheridan. I headed there by turning left along Moraga, and then right down Graham. The building itself is easy to spot, standing alone in the middle of the green near the Disney Museum, and right now is open 10am to 4pm on the weekend, and at other times by appointment.
‘Tree Fall’ is a giant eucalyptus fork, jammed into the roof of the 20 foot square building, with the tree and curved ceiling all covered in local clay that’s been allowed to crack naturally as it dries. The effect is like being inside a giant body, staring at arteries, especially as the only light is what comes in through the door way. The docent was able to give us some background too, apparently the piece is expected to stay for the next three or four years, and the binding they used for the clay was hair from a salon around the corner from my house. There’s apparently a new documentary coming too, and shows Andy’s children, who were young kids in the 2000 film, coming out to San Francisco to help assemble this piece.
Looking at all three works in the same day left me looking at the landscape of the Presidio a little differently, so I hope you get a chance to explore what he’s trying to do too.









