When I talk to people outside of Google and the subject turns to neural networks I often encounter a lot of skepticism. Anybody who’s been alive over the past two decades has seen a lot of technological fads appear in an explosion of hype and fade away without making much of a lasting impact. Remember fuzzy logic, CORBA, or the Semantic Web?
Deep learning is different, and I believe this fervently because is that I’ve seen the approach deliver record-beating results in practical applications across an amazing variety of different problems. That’s why TensorFlow is so important to me personally, because it’s a great platform to share some very down-to-earth tools that demonstrate convincingly how powerful the technique can be. That’s a big reason I’ve tried to build approachable tutorials for common needs like image recognition, so everyone has a chance to see it working for themselves.
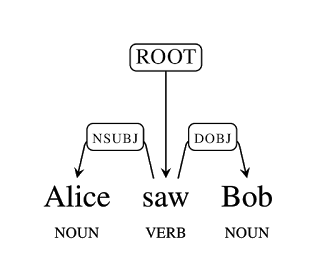
It’s also why I was over the moon to see another Google research team release Parsey McParseface! This is a state of the art sentence parser that’s built using TensorFlow. That might sound a bit esoteric, but parsing is one of the fundamental problems that computers need to tackle to understand written language. With this available, I’m starting to dream up all sorts of interesting applications I wouldn’t have been able to think about before. For instance I’d love to know what verbs and adjectives are most commonly applied to men and women in all sorts of different contexts. To illustrate my point, here’s a paragraph from a great article on why bossy is so gendered:
Finally, the most flexible approach is one that is much more labor intensive. It involves gathering a random sample of instances of bossy and then simply reading through all of them with our own eyes to determine who is being labelled bossy. This is the approach I took in my recent blog post. Because of the amount of time involved, I looked at far fewer examples than any of the approaches I’ve discussed, but I also was able to classify instances that the above approaches would have missed. The graph below illustrates what I found, namely that bossy was applied to women and girls three times more frequently than it was to men and boys. … You might think to yourself, “But there’s only 101 examples! That’s so few!”
This kind of attribution of an adjective to a subject is something an accurate parser can do automatically. Rather than laboriously going through just a hundred examples, it’s easy to set up the Parser McParseface and run through millions of sentences. The parser isn’t perfect, but at 94% accuracy on one metric, it’s pretty close to humans who get 96%.
Even better, having the computer do the heavy lifting means that it’s possible to explore many other relationships in the data, to uncover all sorts of unknown statistical relationships in the language we use. There’s bound to be other words that are skewed in similar or opposite ways to ‘bossy’, and I’d love to know what they are!
That’s just one example though. The reason I’m so excited about deep learning is that I can’t even imagine all the applications that have now become possible. Download Parser McParseface yourself and give it a try on a problem you care about, I’d love to see what you come up with!

Pingback: HTML Tutorial and Web History lesson « BCmoney MobileTV